Créer sa première base de données avec MongoDB

Il y a des technologies qui, lorsqu’on en entend parler, nous font directement penser à d’autres technologies.
Et c’est le cas lorsqu’on aborde la technologie NodeJS. Les 2 principaux termes qui reviendront souvent, et qui sont associés à ce dernier, sont: la MEAN Stack et MongoDB.
La MEAN Stack décrit un environnement complet pour développer une application utilisant MongoDB pour le stockage des données, Express et NodeJS pour la partie serveur et Angular pour la partie visuelle.
Base de données MongoDB
MongoDB est donc un type de base de données très spécifique puisqu’il repose sur le NoSQL qui est à l’opposé du modèle relationnel que l’on connait tous avec le SQL.
Pour mieux comprendre les différences, tu peux retrouver mon article sur les différentes bases de données. (J’accède à l’article)
Cet article va se concentrer sur la découverte et la mise en place de ta première base de données MongoDB. On verra aussi comment connecter cette dernière à une application NodeJS.
Avant tout chose, il existe 2 possibilités pour créer une base de données Mongo: soit on s’occupe nous-même d’héberger notre BDD sur un serveur que l’on maintient soit on passe par une solution cloud comme Atlas
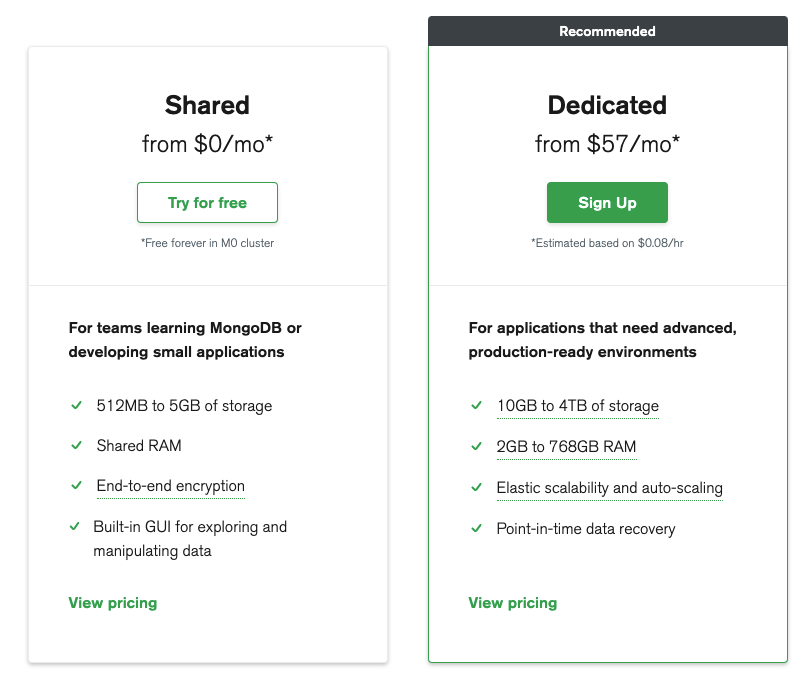
Pour cet article, j’ai décidé d’utiliser la solution cloud Atlas qui n’est autre que la solution d’hébergement en ligne du site MongoDB.
Cette offre est gratuite et permet de travailler sur une BDD avec des petites performances.
Comme le site l’indique, c’est idéal pour découvrir ou pour de petites applications car la RAM n’est pas dédiée et l’espace de stockage est limité.
Atlas MongoDB 🌍
Avant de pouvoir créer une BDD Mongo, il est nécessaire de se créer un compte sur le site.
Pour cela, on se rend directement sur le site 👉 le lien pour faire un compte
Création d’un compte
Personnellement, j’ai utilisé l’inscription via adresse Gmail pour gagner du temps.
Une fois l’adresse mail sélectionnée, il sera nécessaire d’accepter les termes:

Une fenêtre d’inscription réussie va alors s’afficher durant quelques instants:

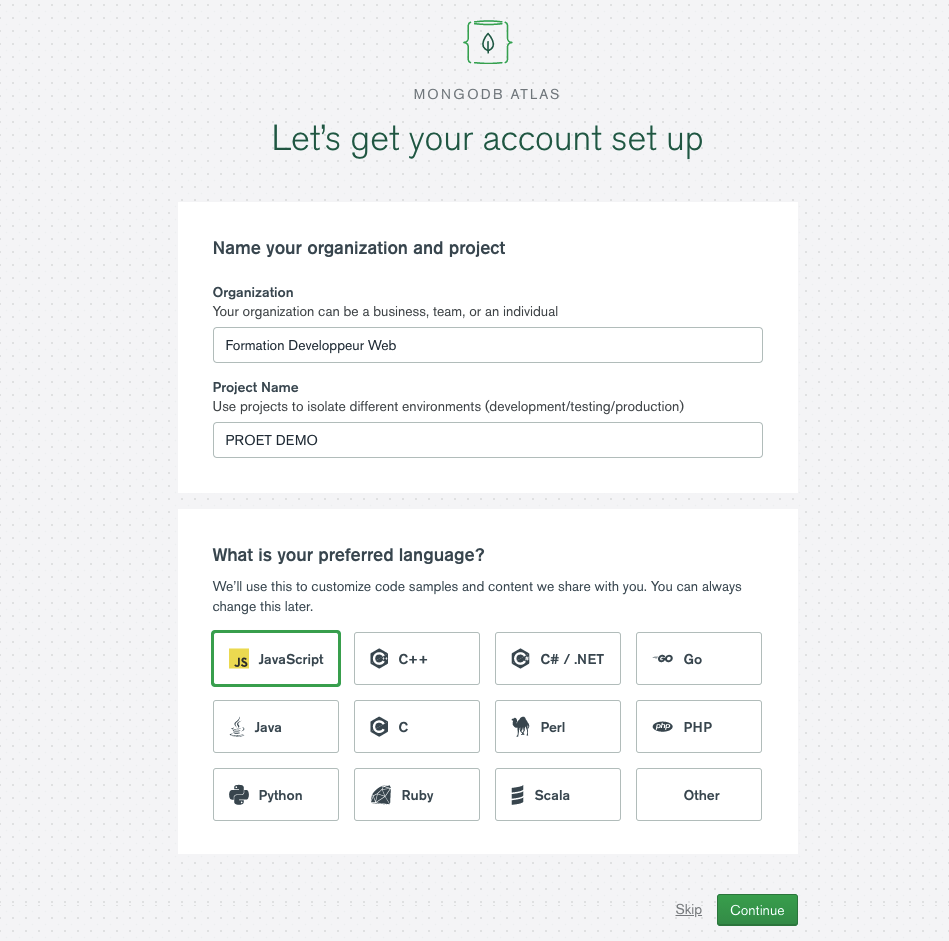
La fenêtre qui suivra nous permettra de renseigner des informations globales pour notre compte.
On retrouvera notamment:
- le nom de l’organisation (mettre son nom ou celui de son entreprise)
- le nom du projet (on pourra en faire plusieurs sur un même compte, pas de soucis)
- le langage préféré (JS ❤️ )
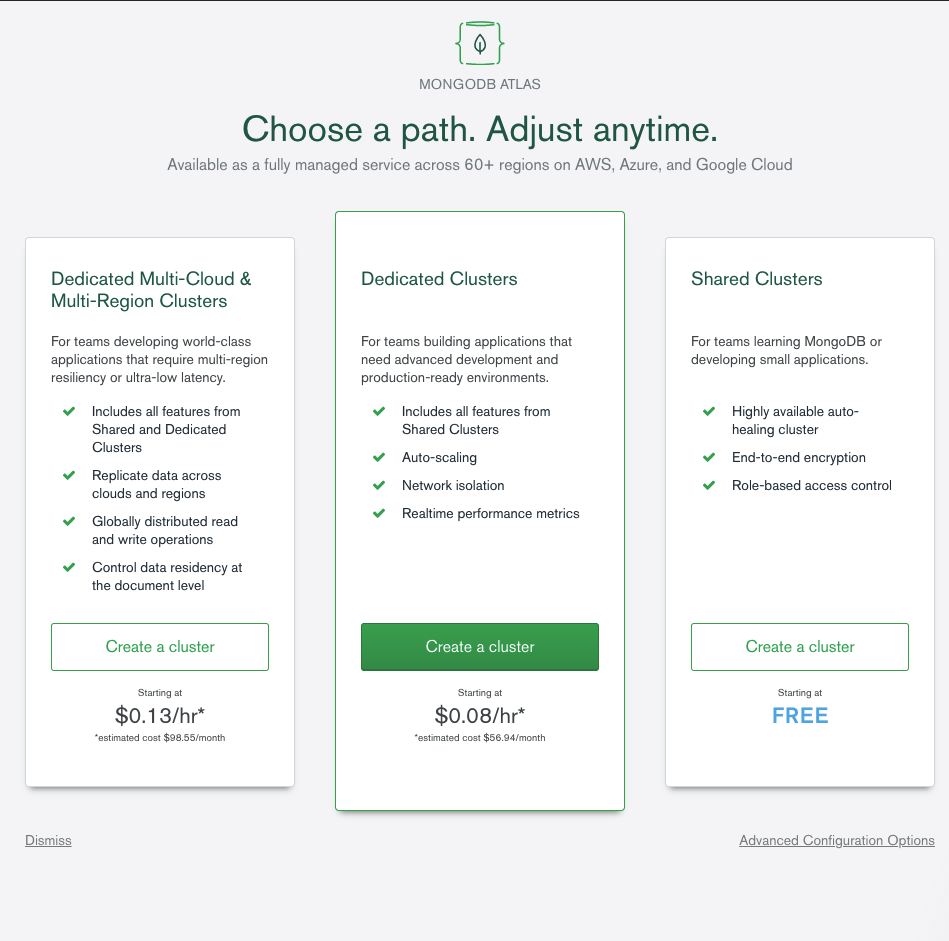
L’étape suivante consistera à choisir son offre, évidemment, nous allons prendre l’offre gratuite:
Il va ensuite être temps de configurer notre cluster.
Création d’un cluster
Chaque projet pourra posséder un ou plusieurs clusters. Un cluster est un groupe de serveurs qui permet de faire, notamment, de la redondance de données.
MongoDB déploiera gratuitement 3 instances répliquées, cela signifie que si l’une des instances n’est plus accessible car elle a crashé, une des 2 autres restantes prendra le relais. C’est donc un véritable gage de haute disponibilité d’application.
Cependant, il ne faut pas confondre avec une sauvegarde. La redondance de données permet d’être sûr que le service sera toujours disponible quoi qu’il puisse arriver, ou presque, car si comme OVH le bâtiment prend feu, tous les clusters seront éteints et la base de données ne sera plus accessible.
Les grosses sociétés ont donc des clusters sur des mêmes positions géographiques pour gagner du temps en cas de crash, mais aussi des clusters sur d’autres positions géographiques pour éviter les soucis qu’on eu OVH.
Le cluster représente donc le choix de la position géographique et de la capacité du serveur. Une fois déployé, pour un même projet, on pourra créer plusieurs bases de données sur le même cluster et pour un même projet.
Il n’y a pas de limite, hormis celle de la taille maximale de 5Go dans la version gratuite.
Configurons notre cluster en 4 étapes.
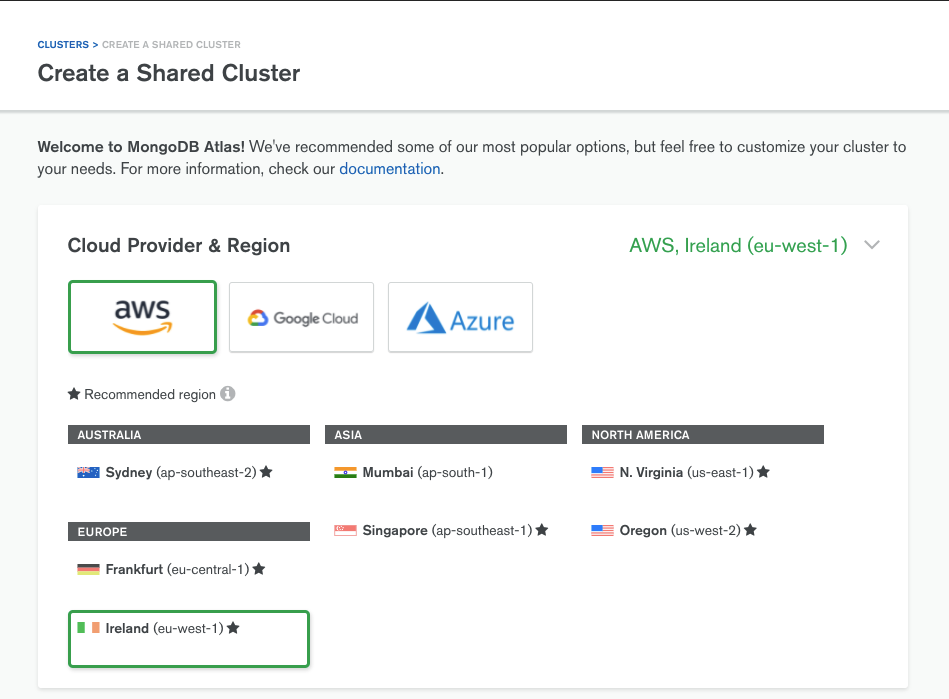
Dans un premier temps, on va choisir la position géographique mais aussi le service qui va héberger notre cluster.
Personnellement, j’ai choisi le service AWS d’Amazon. Pour la position géographique, je vous invite à prendre l’Irlande pour avoir un temps de latence assez faible.
Dans un second temps, il est nécessaire de choisir la formule au niveau de la RAM, du stockage et du processeur.
On peut voir qu’en réalité, la version entièrement gratuite ne nous permet de stocker que 512Mo de données. La version 2 et 5Go étant payante.
On restera donc sur l’option par défaut.

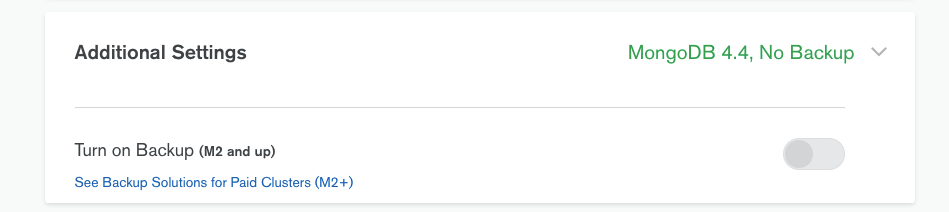
La troisième étape de configuration représente une option de sauvegarde.
Comme expliqué précédemment, l’utilisation d’un cluster est différente d’une sauvegarde et dans la version gratuite, il n’est malheureusement pas possible de sauvegarder automatiquement via le cloud notre base de données.
Il existera cependant des possibilités de le faire via de la programmation.
On laisse donc tout par défaut.
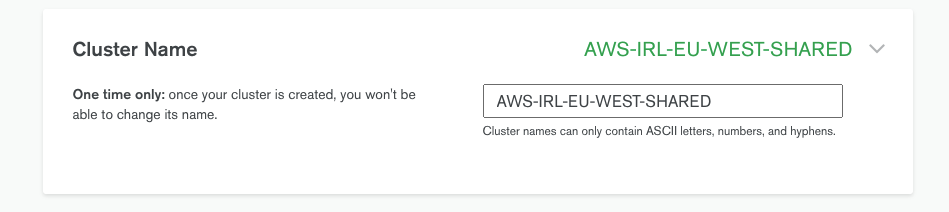
Dernière étape, nous allons donner un nom à notre cluster.
Personnellement, la nomenclature que je vais utiliser est assez simple.
Je reprends le nom du service AWS, la géolocalisation IRL-EU-WEST et le fait que les ressources soit partagées SHARED.
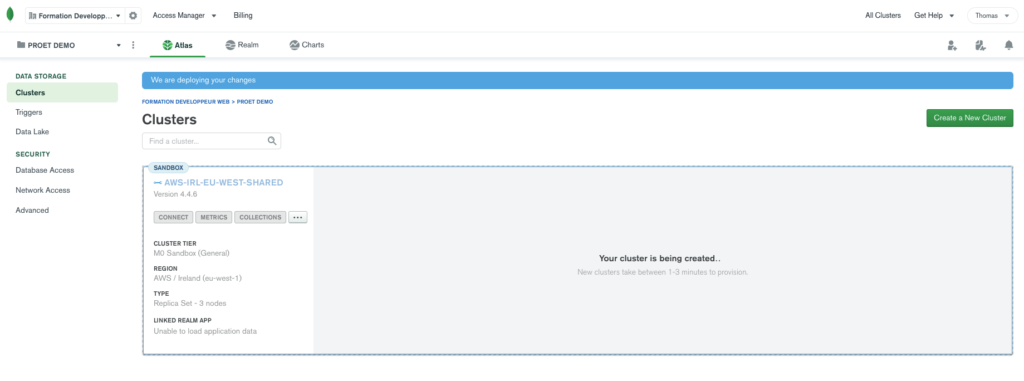
Et c’est tout, il n’y a plus qu’à continuer.
Nous allons être redirigé sur la page de notre projet nous indiquant que le cluster est entrain d’être déployé.
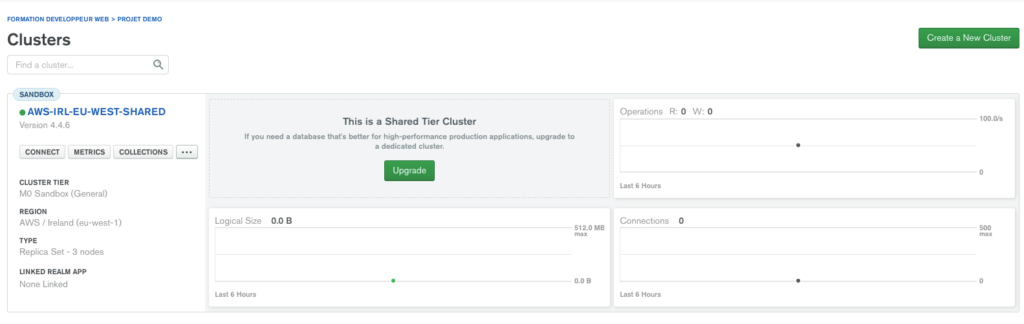
Cela prendra quelques minutes, puis l’interface centrale affichera de nouvelles informations:
Paramétrage d’un accès utilisateur
Notre cluster étant prêt à l’utilisation, il va être nécessaire de pouvoir se connecter à ce dernier pour récupérer les futures données stockées.
Pour cela, nous allons devoir créer un utilisateur.
Globalement, il existe 2 types d’utilisateurs:
- celui qui peut lire et écrire
- celui qui peut seulement lire
Nous allons créer un utilisateur avec les droits de lecture et écriture afin de pouvoir travailler convenablement.
Sur le menu de gauche, on va se rendre sur Security > Database Access:
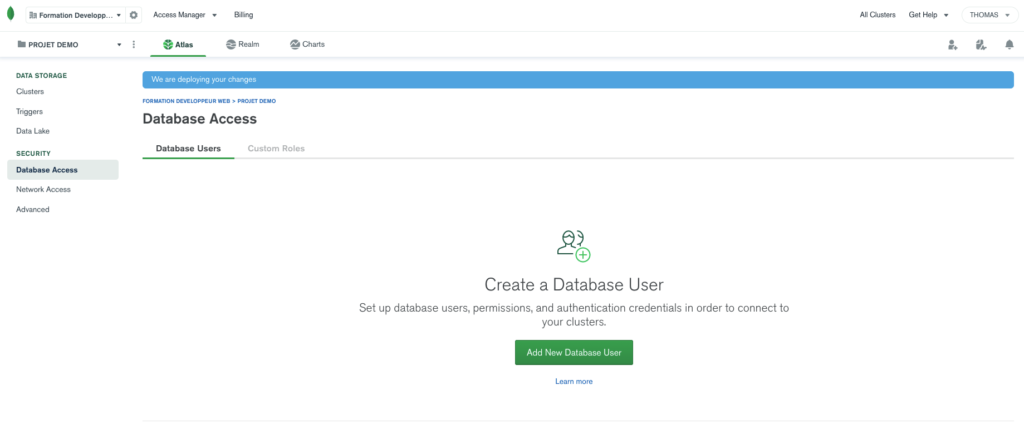
On va cliquer sur le bouton permettant d’ajouter un utilisateur et on va remplir la popup comme suit: (j’ai utilisé la génération automatique de mot de passe)
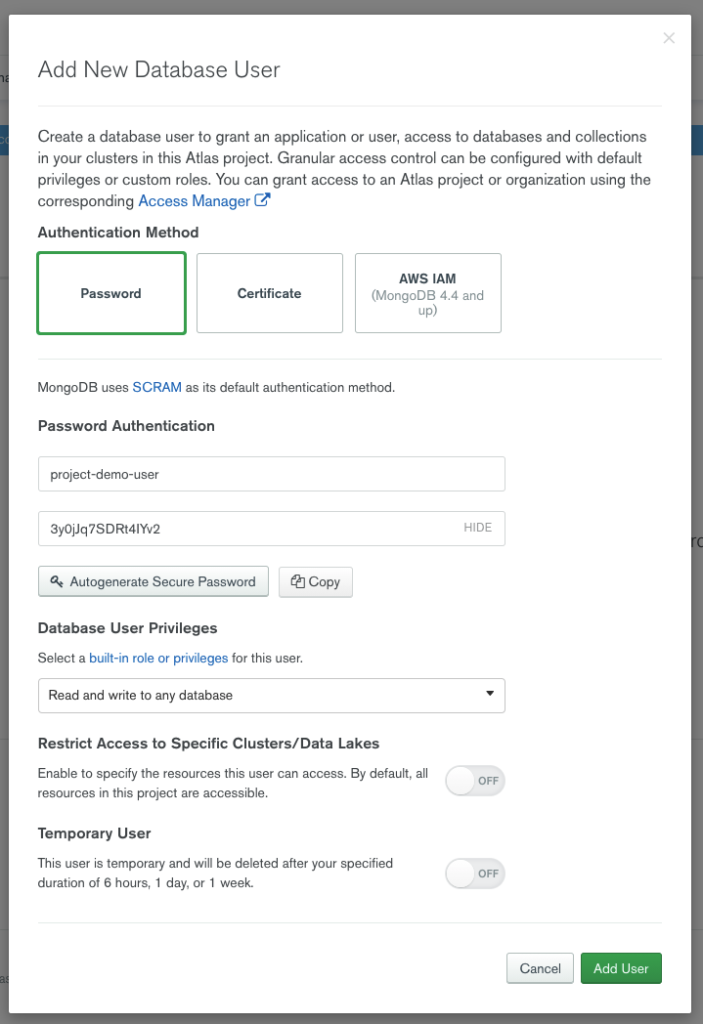
On accepte et notre utilisateur devrait apparaitre sur l’interface.
Sécurisation de l’accès à la base de données
Notre utilisateur étant maintenant créer, par défaut le cluster n’est pas accessible pour des questions de sécurité !
Il va donc falloir dire au cluster que nous donnons accès à une IP précise ou bien une plage d’adresse IP ou bien tout simplement à tout le monde.
Pour des raisons de sécurité et dans la plupart des cas, on restreindra l’accès à une adresse IP précise. Ce sera souvent celle du serveur API qui se connectera ou bien celles des postes des développeurs.
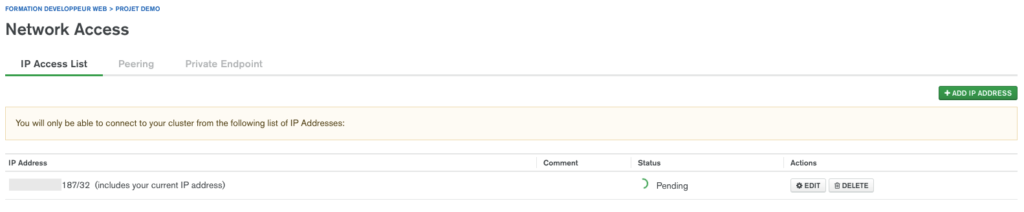
Sur le menu de gauche, on va se rendre sur Security > Network Access:
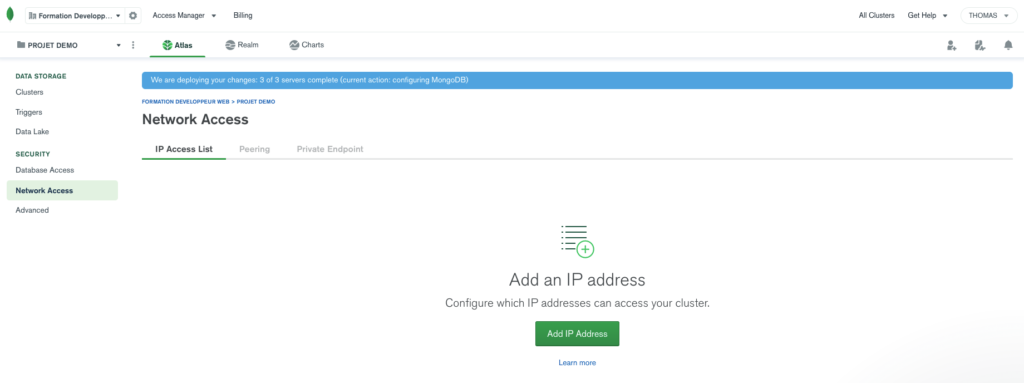
On va cliquer sur le bouton permettant d’ajouter une nouvelle adresse IP: (j’ai cliqué sur le bouton ADD CURRENT IP ADDRESS)
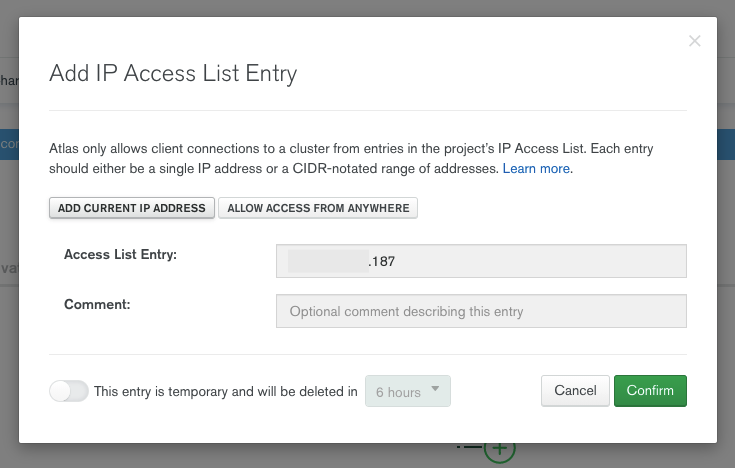
On accepte et notre adresse IP devrait apparaitre sur l’interface:
Création d’une base de données
Nous allons maintenant pouvoir créer notre première base de données ! 🎉
On retourne sur la page principale en cliquant sur Data Storage > Clusters, puis, on va pouvoir cliquer sur le bouton COLLECTIONS au niveau de notre cluster:
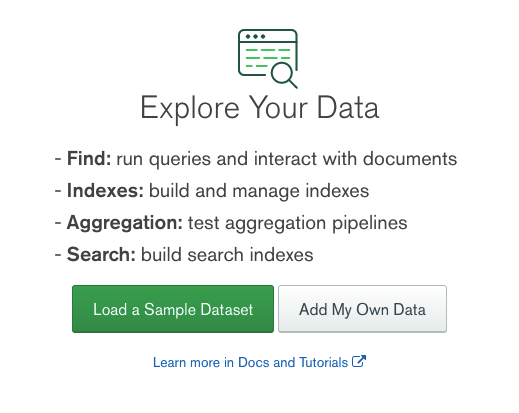
Le site va nous dire qu’il n’existe pas de données pour le moment et qu’il y a deux possibilités:
- MongoDB nous met à disposition des données pour tester
- on crée nos propres données
Nous allons choisir la deuxième option et cliquer sur Add My Own Data:
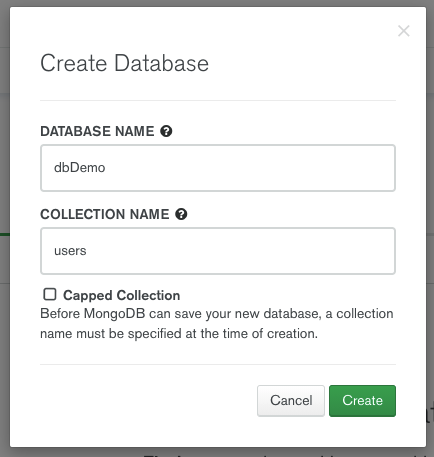
Dans la popup qui va s’ouvrir, nous allons pouvoir donner un nom à notre base de données et nous allons aussi pouvoir créer notre première collection (pour rappel c’est l’équivalent d’une table en SQL):
Une fois crée, une nouvelle interface nous montrera notre base de données mais aussi les différentes collections et données que nous avons, c’est à dire, aucune pour le moment.
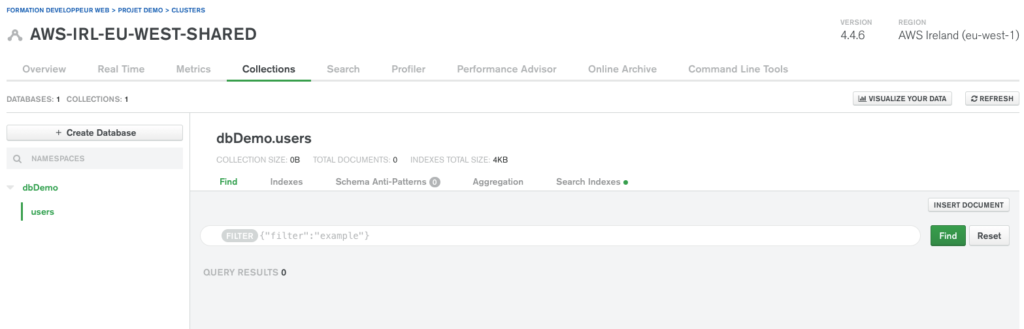
Nous allons ajouter à la main une donnée que l’on pourra ensuite récupérer.
Tout à droite, nous avons un bouton INSERT DOCUMENT:
On clique dessus et nous allons créer un document représentant un possible utilisateur.
On va remplir comme suit:
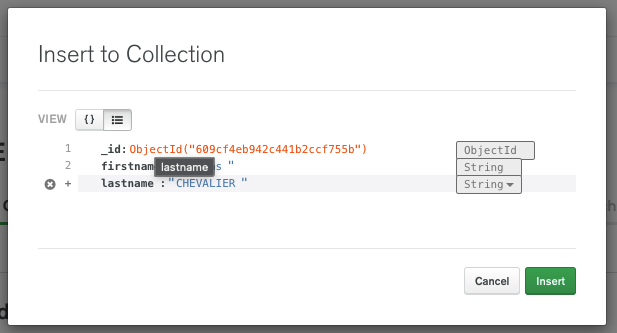
Pour ajouter un nouveau champ, il faut se positionner sur la dernière ligne, l’affichage va ainsi montrer une croix (pour supprimer) et un + (pour ajouter):

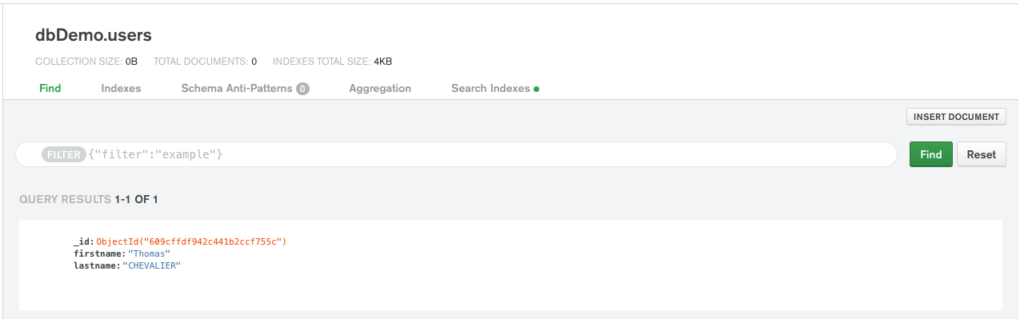
On clique ensuite sur Insert et notre données devraient apparaître sur l’interface:
NodeJS & MongoDB 🤝
Nous avons maintenant fini l’installation, la configuration et la création de notre base de données.
Il est temps de se connecter à celle-ci avec un projet NodeJS.
Nous allons créer de manière très simple un rapide projet NodeJS, faire la connexion et récupérer notre utilisateur.
Création du projet
On va commencer par créer un dossier et instancier un fichier package.json.
On se positionne avec un terminal à l’endroit où l’on souhaite créer le dossier puis on exécute les commandes:
mkdir nodejs-mongodb cd nodejs-mongodb npm init -y
On a ensuite besoin d’installer le driver MongoDB qui nous permettra de créer la connexion et de faire des requêtes:
npm i --save mongodb
On oublie pas d’ajouter un script start dans le fichier package.json et de changer le point d’entrée index.js en server.js:
{
"name": "nodejs-mongodb",
"version": "1.0.0",
"description": "",
"main": "server.js",
"scripts": {
"start": "node .",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"mongodb": "^3.6.6"
}
}
Connexion à notre cluster
Avant de nous connecter à notre cluster, il faut que l’on crée notre fichier de serveur.
touch server.js
Puis, on va pouvoir le modifier en ajoutant la connexion et on va essayer de récupérer la liste des bases de données disponibles sur le cluster.
Fichier server.js:
const { MongoClient } = require('mongodb');
const uri = "mongodb+srv://project-demo-user:3y0jJq7SDRt4IYv2@aws-irl-eu-west-shared.loxwv.mongodb.net/dbDemo?retryWrites=true&w=majority";
// On configure le client de connexion
const client = new MongoClient(uri, { useNewUrlParser: true, useUnifiedTopology: true });
// On établit la connexion
client.connect(async err => {
// On récupère la liste des BDD
const dbList = await client.db().admin().listDatabases();
// On les affiche
console.log("Databases:");
dbList.databases.forEach(db => console.log(` - ${db.name}`));
// On ferme la connexion avec Mongo
await client.close();
});
Attention, pour configurer l’URI de connexion, il faut retourner sur Data Storage > Clusters et au niveau du cluster, on verra un bouton CONNECT:
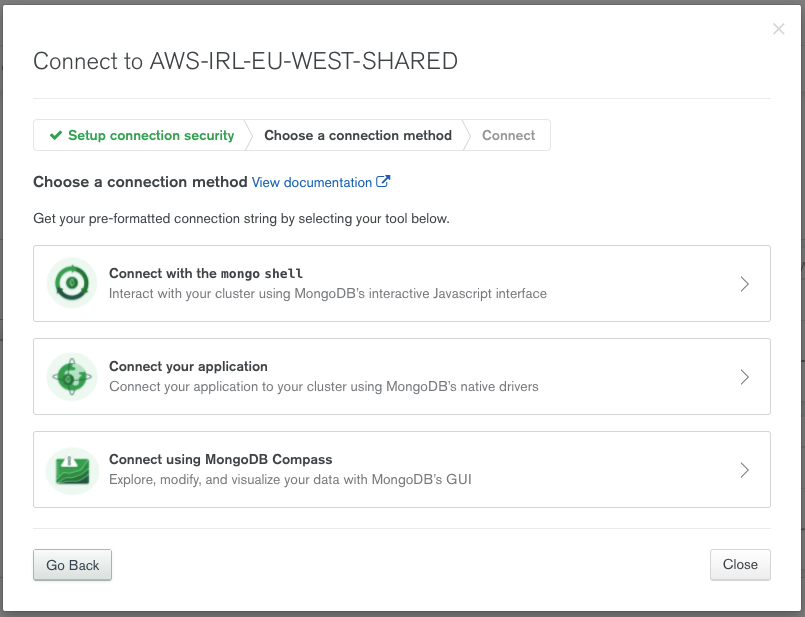
Dans la popup, on sélectionnera Connect your application:
Dans la nouvelle fenêtre qui s’ouvrira, on trouvera une URI complète, quasiment prête à l’emploi !
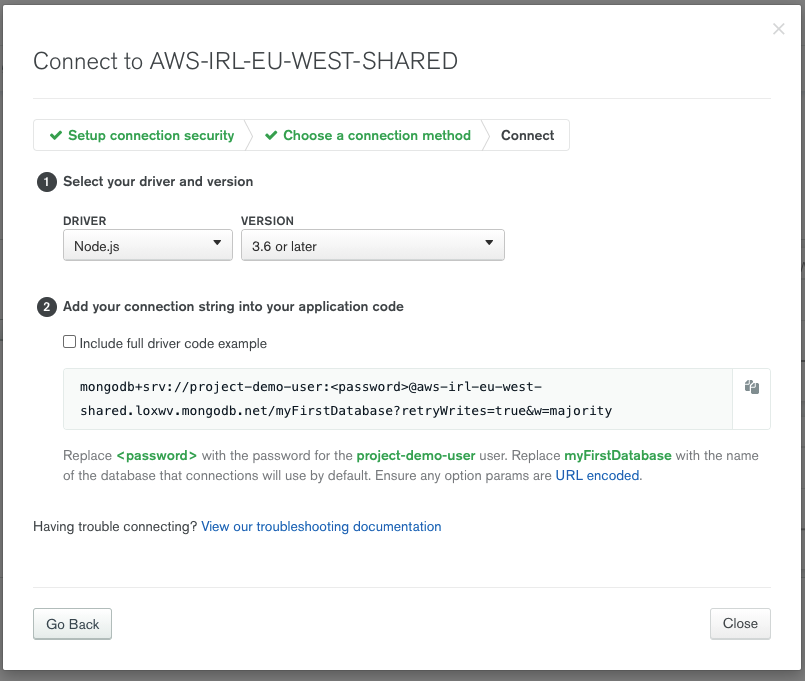
Il faudra ajouter le mot de passe de notre utilisateur mais aussi modifier le nom de la base de données qui est par défaut, chez eux, myFirstDatabase. (De notre côté, nous l’avons appelé dbDemo)
Il ne reste qu’à lancer le projet et vérifier le rendu:
npm start
Et, dans la console, on devrait voir apparaitre le nom des bases de données disponibles:
Databases: - db-demo - admin - local
Récupération de notre utilisateur
Nous allons maintenant essayer de récupérer notre utilisateur.
Pour cela, il va falloir se positionner sur la bonne collection, puis exécuter une requête dessus.
Fichier server.js:
const { MongoClient } = require('mongodb');
const uri = "mongodb+srv://project-demo-user:3y0jJq7SDRt4IYv2@aws-irl-eu-west-shared.loxwv.mongodb.net/dbDemo?retryWrites=true&w=majority";
const client = new MongoClient(uri, { useNewUrlParser: true, useUnifiedTopology: true });
client.connect(async err => {
// On cible la BDD et la collection dans cette BDD
const Users = await client.db('dbDemo').collection('users');
// La méthode find permet de récupérer toutes les données sans critère
// Le toArray convertit le retour de la fonction en un tableau
const users = await Users.find().toArray();
// On boucle sur chacun des éléments et on l'affiche
users.forEach(user => console.log(`Je m'appelle ${user.firstname} ${user.lastname}`));
await client.close();
});
Le résultat:
Je m'appelle Thomas CHEVALIER
Conclusion
Le fonctionnement de MongoDB est assez simple dans l’ensemble et il est surtout très intuitif lorsqu’on est très proche du monde Javascript puisque le format de données se rapproche du format JSon.
La connexion et la création d’une requête est assez simple dans cette exemple et les possibilités de MongoDB vont bien au-delà de ce que l’on a pu voir.
Le Cloud Atlas possède une prise en main rapide et facile et permet de rapidement se concentrer sur le code plutôt que sur la gestion d’un serveur une fois qu’on a pris l’habitude de travailler avec.
Enfin, nous avons utilisé dans cet article le driver Mongo mais dans des applications à destination d’utilisateurs, on préfèrera utiliser une librairie, tel que Mongoose, permettant de jouer le rôle d’ORM (librairie qui fait la liaison entre un objet dans un langage et une base de données relationnelle) qui, dans le monde NoSQL s’appelle un ODM puisqu’on ne gère pas des relations mais des documents.



