Base de données
Lorsqu’on débute la programmation, on est souvent concentré sur la création d’algorithme pure et bien souvent, on développe des logiciels et programmes simples qui ne demandent aucun stockage de données.
Et puis, au fur et à mesure de l’apprentissage, on souhaite que nos données soient stockées, c’est à dire que chacune de nos modifications soient inscrites à un endroit et qu’à la prochaine ouverture de notre application, on ne reparte pas de zéro.
On fait quelques recherches et on tombe sur les notions de bases de données ou encore de persistance de données.
Plus on avance dans nos recherches, plus on se rend compte que c’est un univers vaste et riche.
Sauvegarder des données
La persistance de données est le fait de rendre définitif une action effectuée sur une donnée.
Imaginons que tu développes une application permettant de gérer tous les jeux de plateau que tu as en ta possession. Tu n’as pas envie de remettre à chaque fois les informations que tu as déjà mise la fois précédente. Il va donc être nécessaire que cet ajout ou modification de données soient sauvegardées quelque part.
Il en est de même si tu crées une application pour le Web. Tu ne souhaites pas que tes utilisateurs, qui ajoutent ou modifient des données sur ton site, perdent ces données.
Il va donc être nécessaire d’utiliser un outil permettant d’effectuer cette sauvegarde définitive, on appelle cela une base de données ou BDD.
Grossièrement, c’est un énorme tableau dans lequel on va ranger nos informations. Quand on aura besoin d’une donnée spécifique, on récupérera les informations sur la ligne du tableau correspondante et quand on aura besoin de la modifier ou la supprimer, on fera de même.
Un fichier Excel est un très bel exemple de stockage massif et structuré. Chaque feuille d’un fichier Excel permet de cloisonner le type donnée que la feuille va contenir et on peut avoir des relations entre les différentes feuilles.
Cette technologie va donc permettre de centraliser à un endroit précis toutes les informations pour une même application et pour des utilisateurs différents.
Voici un schéma d’exemple:
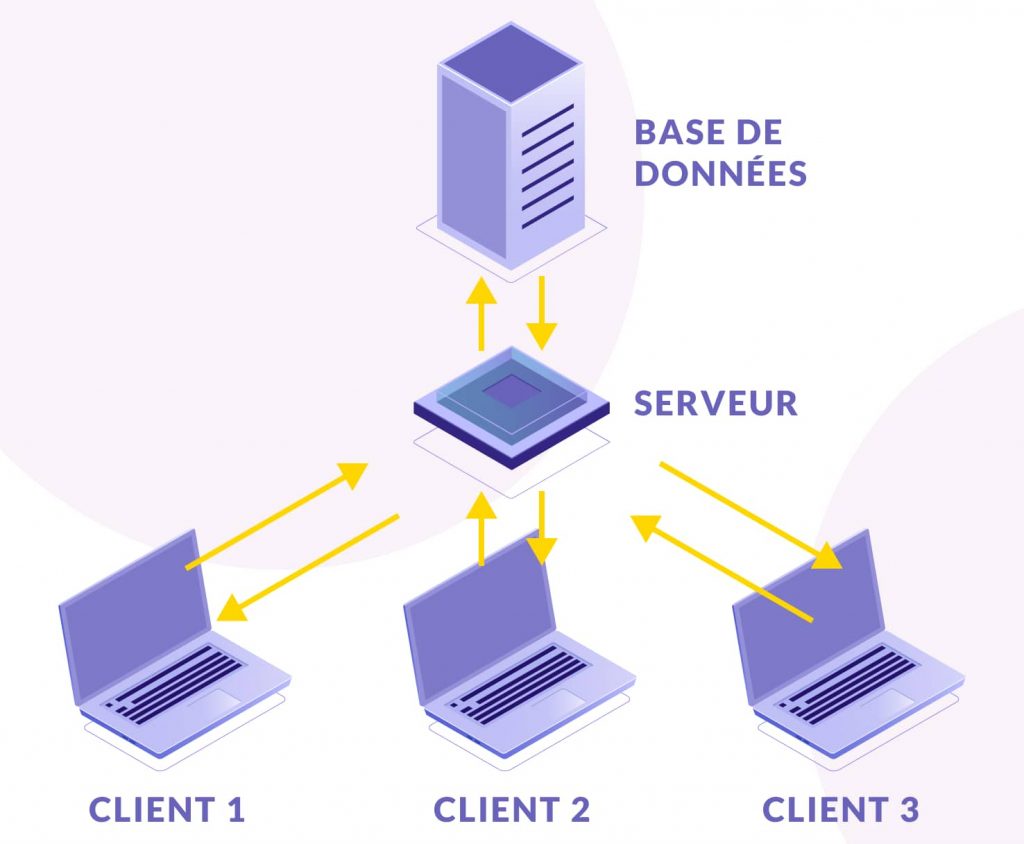
On peut voir que chacun des clients, qui sont des ordinateurs, des tablettes ou des téléphones, vont se connecter à un serveur sur lequel se trouvera notre code. Ensuite ce serveur va tout simplement se connecter à une banque de données qui comportent l’intégralité des informations de notre application.
Ainsi, tout le monde a accès au même ensemble d’informations !
Comment utiliser une base de données ?
Pour pouvoir sauvegarder des informations dans ce type de stockage, il va être nécessaire de faire 2 choses:
- créer une base de données
- établir une connexion avec celle-ci
Avant de créer une BDD, il va falloir choisir son type. Quelques années en arrière, le choix était assez simple car il était possible de ne faire que de la persistance dite relationnelle (pour du stockage en ligne) ou sous forme de fichiers fichiers (pour du stockage hors-ligne)
Aujourd’hui, le monde a évolué et, un nouveau type de banques de données a vu le jour notamment avec les GAFA (Google Amazon Facebook Apple). Ce type de base se nomme NoSQL car il est tout l’opposé d’une base relationnelle, c’est à dire que la base est non structurée et dénuée de relations.
Je reviendrais sur les types un peu plus tard dans cet article. Concentrons-nous sur le deuxième point à savoir comment établir une connexion.
Et bien, comme on a pu le voir dans le schéma précédent, la base de données est forcément reliée à un serveur qui permet de faire le pont entre ce que demande le client et ce qu’elle possède. Et c’est donc à travers ce serveur que l’on va établir la connexion.
Pour être encore plus précis, cela va être le rôle du langage backend utilisé. Par exemple, si tu as développé ton application avec du PHP pour la partie backend et bien se sera au PHP de se connecter et de discuter avec la banque de données.
En effet, c’est la partie serveur qui doit avoir accès à ces données car elle aura souvent besoin de les manipuler pour les renvoyer correctement mis en forme pour le client.
Chaque langage serveur possède sa propre manière de se connecter à un stockage massif et structuré. Les documentations sont relativement bien faites pour ce point car c’est devenu un incontournable.
Les bases de données relationnelles
Quand on parle de base de données, souvent, les premières choses que l’on entend sont les mots relationnel et SGBDR.
Le premier mot renvoie à la manière dont va être modéliser la BDD, c’est à dire avec un modèle de relations.
Le second mot renvoie à l’outil qui permet d’accéder et de manager une banque de données, car oui, on ne va pas re-développer la roue, il existe des outils qui permettent d’administrer toutes ces données (PhpMyAdmin par exemple).
Revenons sur le modèle relationnel et prenons un exemple pour bien le comprendre.
La France est composée de régions qui possèdent chacune des villes.
Le modèle de ce type de base de données repose sur le fait qu’il existe la plupart du temps des relations au sein du stockage. Et c’est exactement le cas dans l’exemple que j’ai pris.
Une ville appartiendra à une seule région et on pourrait avoir besoin de récupérer toutes les villes selon une région spécifique.
Ainsi, plutôt que d’avoir un unique tableau avec des informations redondantes et difficilement maintenables et bien on va exporter ces informations dans un second tableau et relier les 2 tableaux ensembles.
Exemple avec un seul tableau:
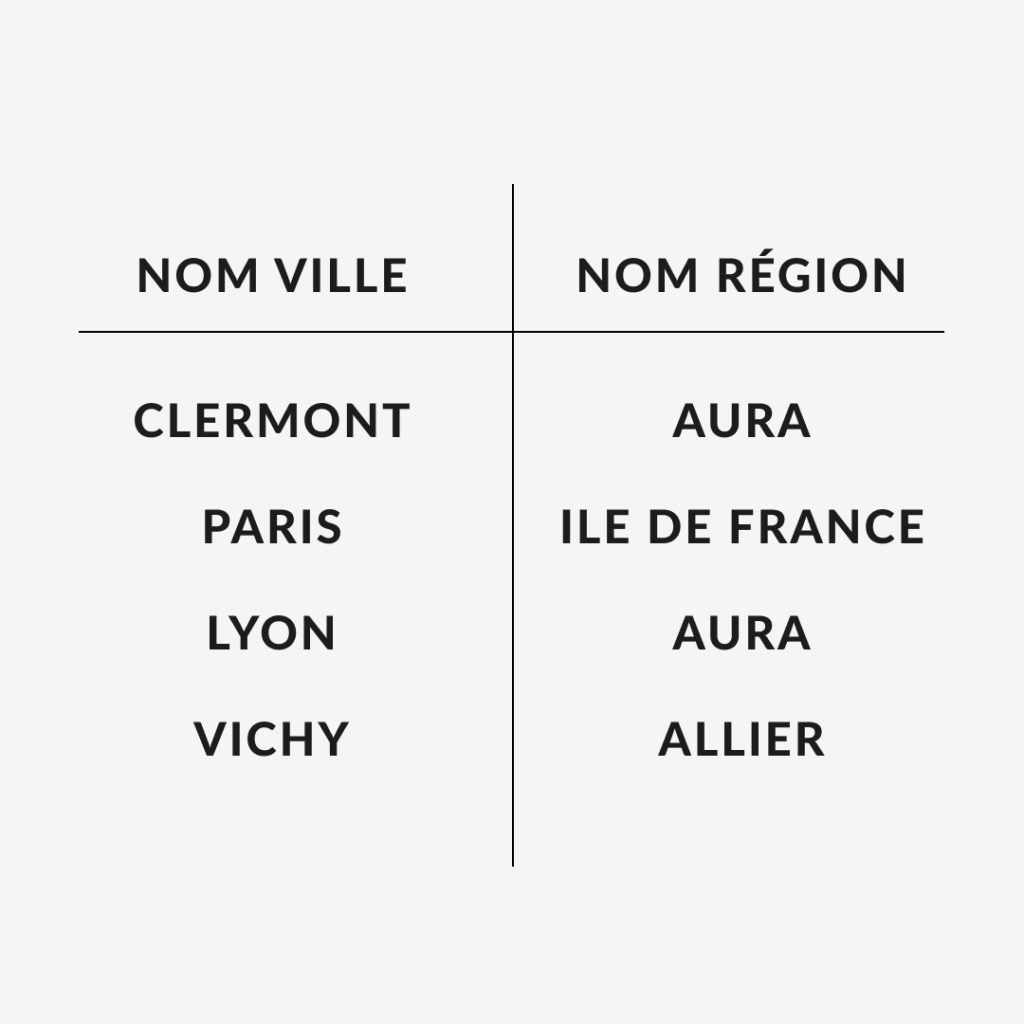
Dans cette exemple, on voit clairement que, si il est nécessaire de faire une modification sur le nom de la région Auvergne Rhône Alpes, il faudra intervenir sur chacune des villes qui l’utilise. Il est aussi totalement possible que quelques fautes d’orthographe viennent s’ajouter et rendre difficile la récupération d’informations.
Voyons maintenant le même exemple avec 2 tableaux:
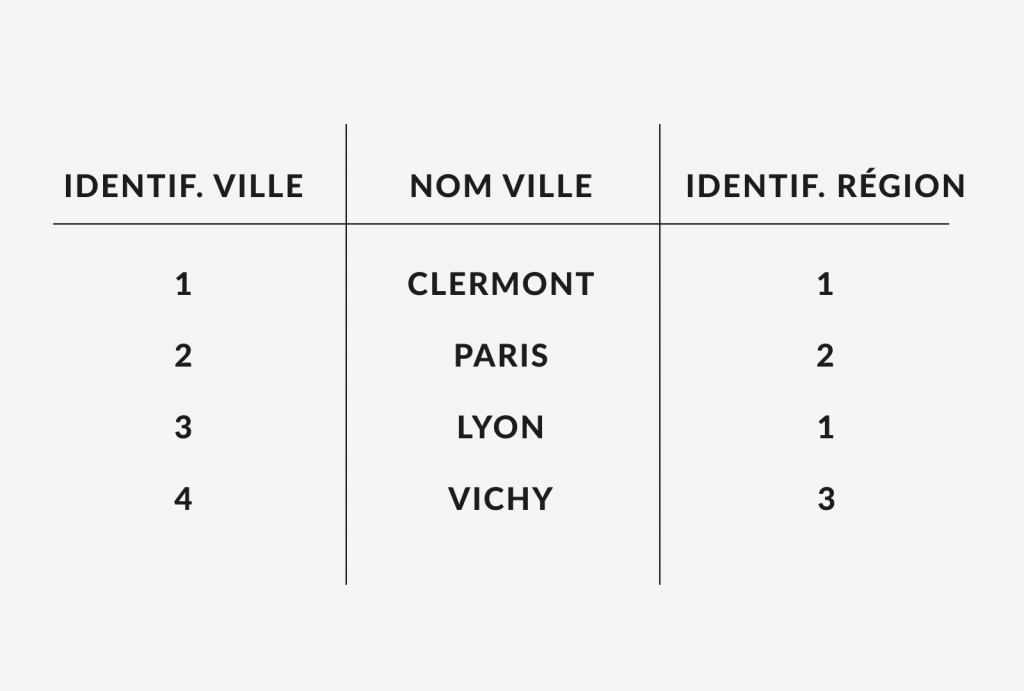
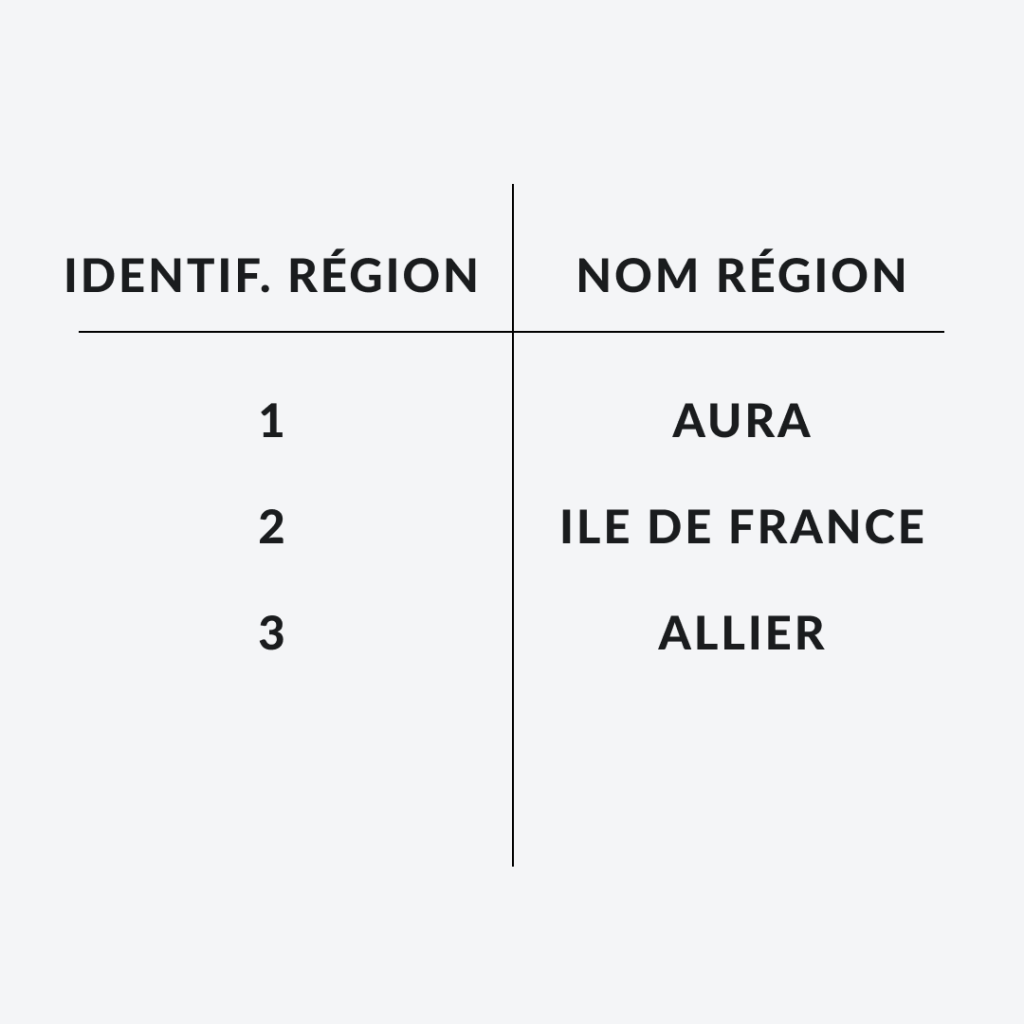
On intègre ici le modèle de relation grâce à des identifiants uniques. Chaque ville va posséder un identifiant et aura une référence de l’identifiant de la région dans laquelle elle se trouve.
On appelle l’identifiant la clé primaire et l’identifiant faisant référence à une relation, la clé étrangère. On appellera un tableau, une table et chaque élément du tableau une entrée.
Ainsi, si l’une des régions changent de noms, pas de panique, il n’y a qu’un seul endroit à modifier puisque tout le reste n’est qu’une question de relations.
Il en va de même pour récupérer toutes les villes d’une région: il suffit de connaitre l’identifiant de la région, exit les problèmes de fautes de frappe.
Il reste un dernier point à aborder: le langage.
En effet, il va être nécessaire à un moment donner de faire ce que l’on appelle une requête: récupérer ou modifier des informations selon certains paramètres. Et pour cela, nous allons utiliser un langage propre aux bases de données relationnelles à savoir le SQL. (Structured Query Language ou langage de requête structurée)
Le monde du NoSQL
La famille NoSQL a commencé à exister autour des années 2010. C’est aussi à partir de cette époque qu’on a pu entendre parler du Big Data, de Data Center et de tout ce qui touche de près ou de loin à du stockage massif d’informations.
C’est à partir de ce dernier point que le NoSQL est né. Les volumes de données devenant de plus en plus important, les bases de données relationnelles ne permettaient pas de suivre la mise à l’échelle (scalabilité) d’un système qui évoluait extrêmement rapidement. En effet, le modèle relationnel possède ses propres limites de performances lorsqu’il s’agit de trier un volume énorme de données.
Ceux sont donc les plus grands qui ont lancé chacun leur tour leur propre système de gestion de BDDs NoSQL. On retrouve par exemple Cassandra et HBase chez Facebook, BigTable chez Google, MongoDB chez SourceForge.net ou encore CouchDB pour Ubuntu One.
Mais si on ne fait pas de relations comment cela fonctionne ?
Et bien, le modèle NoSQL peut grossièrement se résumer à un modèle clé/valeur, c’est-à-dire un tableau associatif avec des millions voir des milliards de données.
Il existe évidemment des spécialités dans le NoSQL puisque celui-ci permet de répondre à différents besoins que ce soit du stockage à des fins classiques, à des fins de statistiques ou encore à des fins de graphiques. Il existera donc autant de manière de concevoir et d’utiliser le NoSQL.
Revenons au type de données. Si on prend l’exemple de MongoDB qui est certainement le plus connu et le plus répandu aujourd’hui, on retombe sur un format de données nommé BSON. C’est un dérivé du format JSON qui permet d’être binaire et d’être plus permissif sur les types de valeurs.
Le JSON est lui même un dérivé des objets littéraux Javascript. On comprend pourquoi MongoDB se marie facilement avec des applications NodeJS !
En NoSQL, contrairement au monde relationnelle, on appellera un tableau une collection et chaque ligne du tableau sera un document.
Globalement, le fonctionnement sera assez identique, puisque dans notre cas, on fonctionnera aussi avec une référence de l’identifiant de la Région au sein d’un document Ville.
Exemple avec les villes:
// Collection Ville
[
{
_id: 1,
nom: Clermont-Ferrand,
regionId: 1
},
{
_id: 2,
nom: Paris,
regionId: 2
},
{
_id: 3,
nom: Lyon,
regionId: 1
},
{
_id: 4,
nom: Vichy,
regionId: 3
}
]
Exemple avec les régions:
// Collection Région
[
{
_id: 1,
nom: Auvergne-Rhône-Alpes
},
{
_id: 2,
nom: Île-de-France
},
{
_id: 3,
nom: Allier
}
]
Cependant, la requête de récupération d’informations sera beaucoup plus rapide. Il faut aussi savoir que contrairement au monde relationnel qui possède un langage dédié, le SQL, l’univers NoSQL lui ne possède pas de langage. Chaque technologie NoSQL possède sa propre manière d’interagir avec les données stockées.
Conclusion
Globalement, le but d’une base de données relationnelle ou NoSQL reste le même: stocker des informations.
Si le modèle relationnel est présent depuis de nombreuses années, on a pu voir que son approche n’était pas la plus performante lorsqu’il s’agissait de traiter un volume de données importants.
Le NoSQL, quant à lui, répond parfaitement à cette demande cependant il ajoute sa propre couche de complexité et ses propres spécificités puisqu’il permet de faire de nombreuses choses.
Il reste un dernier type de bases de données que je n’ai pas évoqué dans cet article qui est le stockage au format fichier.
C’est par exemple le cas de SQLite qui est assez connu pour le stockage de données hors-ligne, c’est à dire directement sur le support (ordinateur, tablette ou téléphone). Son fonctionnement se rapproche d’une base de données relationnelles sauf qu’il n’y a pas besoin d’avoir un serveur de stockage. C’est notamment ce que les logiciels utilisent souvent pour sauvegarder les configurations utilisateurs sur un ordinateur ou un téléphone.



